Scraping 101 part 4
Make the change
Let’s try and improve our script and see if we can get the gender.speculate
method to properly identify all names gender. As we can see from our print
out we notice that there is an 'U' in the group 'Universitetslektor':
'Universitetslektor': {'M': 5, 'U': 1, 'F': 4}We can conclude that there someone with the title Universitetslektor who’s
gender we could not identify. Either we did not parse first names correctly or
it is marked as an 'U' because it is not in the gename database. Let’s
first make sure that we did get the names properly extracted from the webpage.
Since we are iterating through all the persons on the staff page, let us just
print out their first name on every loop and have a look. Change the line:
first_name = name.split(',')[1].strip()to:
first_name = name.split(',')[1].strip()
print(first_name)Save the file and run the program again by typing: python scrape_gu.py. Now
you will get a pretty big output, first there is a list of names followed by
the statistics that we saw before, nothing surprising about that right? Now
scroll up the list of names and you should find this name 'Mathias A.'. That
is not a first name and for sure gender.speculate will fail to figure out the
gender here. We need to figure out a way to modify the script in a way that
parses this name correctly. What if we just split the 'Mathias A.' string by the
' ' character and just use the first part, sounds good right? Make the
following change to do this:
first_name = name.split(',')[1].strip().split(' ')[0]
print(first_name)We just appended some stuff directly to the previous result, first we made
the split on ' ' by appending .split(' ') and then we used the first part
by appending [0]. Counting in programming mostly start with 0 and not 1,
I think that is the only difference between man and machine. This all seems
good for the string 'Mathias A.' but what about the other names that do not have
this problem? Well if we split say 'Marianthi' by the ' ' character the first
part of that result would still be 'Marianthi'. Let’s try it out before we
change our program. In our terminal inside VS Code, we just type python.
Now we are in the python interpreter and we can run python commands directly,
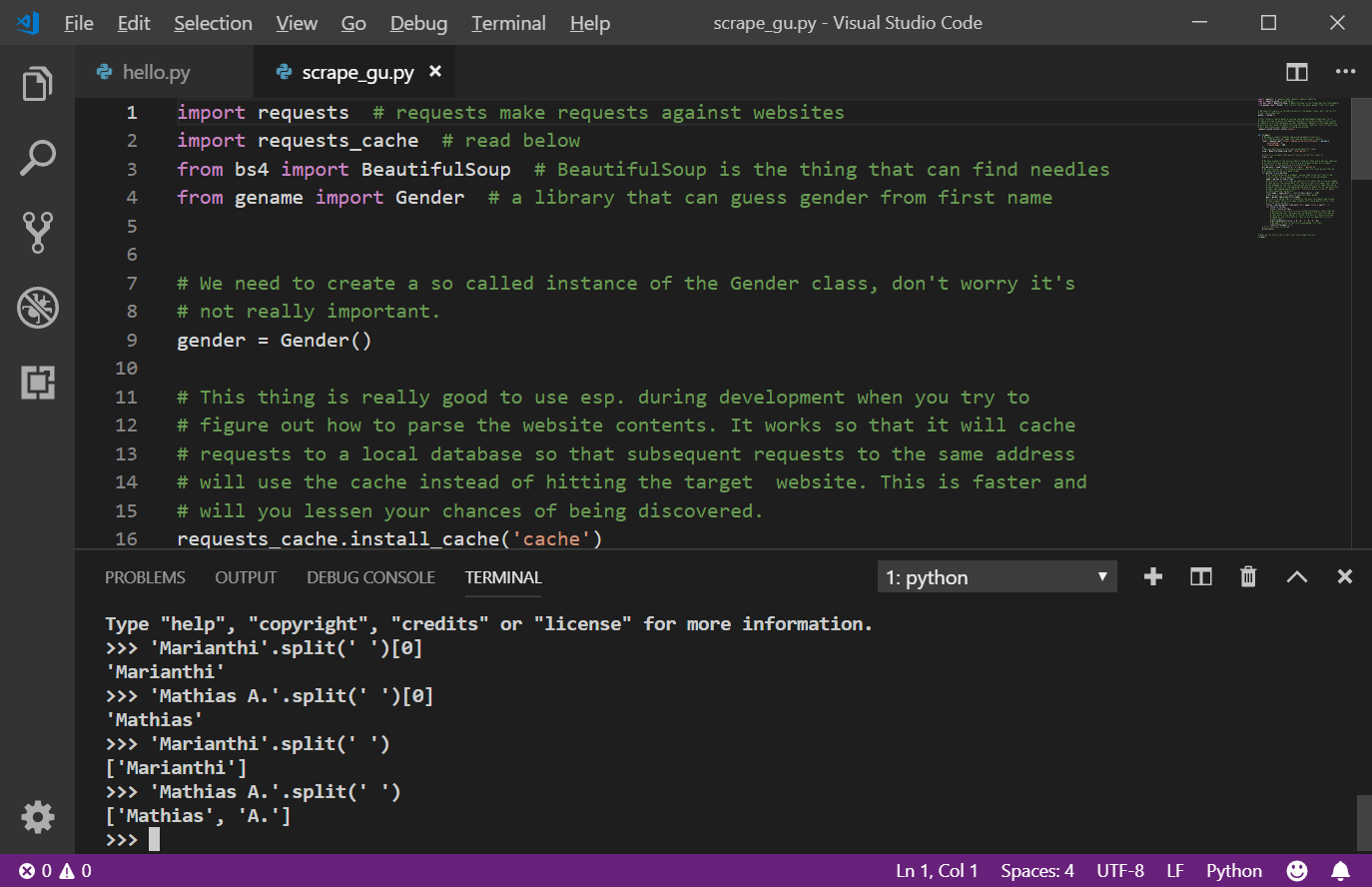
type 'Marianthi'.split(' ')[0], please make sure you enter all the single
quotes correctly. In python you can enter a string with double or single
quotes, I prefer to use single quotes for no particular reason. The output
should be as we hoped for: 'Marianthi'. Now type: 'Mathias A.'.split(' ')[0]
and hit enter to notice that we also this time got the result that we hoped
for. Below you will see the output, I also typed the commands without the
ending [0] which might give you some insight:
Now exit the python interpreter by typing exit(). Now that we have done some
testing we can remove the print line that entered before in our program:
print(first_name)Run the program again by typing python scrape_gu.py in the terminal and you
should see the full stats output that we have aleady seen but in particular:
'Universitetslektor': {'M': 6, 'F': 4, 'U': 0}The 'U' that we had previously has now become an 'M', in this context this
is a good thing.
Hard working academics
Our next challenge is to have all the staff that hold multiple titles properly counted. This change will prove to be a little bit more complicated, don’t worry if you don’t understand everything.
We have seen in our output things like:
'Universitetslektor, Prefekt': {'M': 0, 'F': 1, 'U': 0}Does this problem seem somewhat familiar? We should be thinking about how to split this string into multiple strings. We could split on comma, right? The only extra problem we will end up with then is that we will have more titles than persons. Ok, let’s try to implement this idea into our code, change the line:
title = person.find_next('td').span['title']Into:
titles = person.find_next('td').span['title'].split(',')Ok, now what, we changed the variable name title into titles and this is
now a list of at least one title and the program that we have is written to
only use one title. We need to make some more changes for the program to work.
As we talked about earlier concerning the following part of the program:
for person in all_persons:That is a loop that will assign every person in all_persons to the variable
person and then run the code inside the loop. We want to do the same thing
here with titles and title. Make the following change to your code:
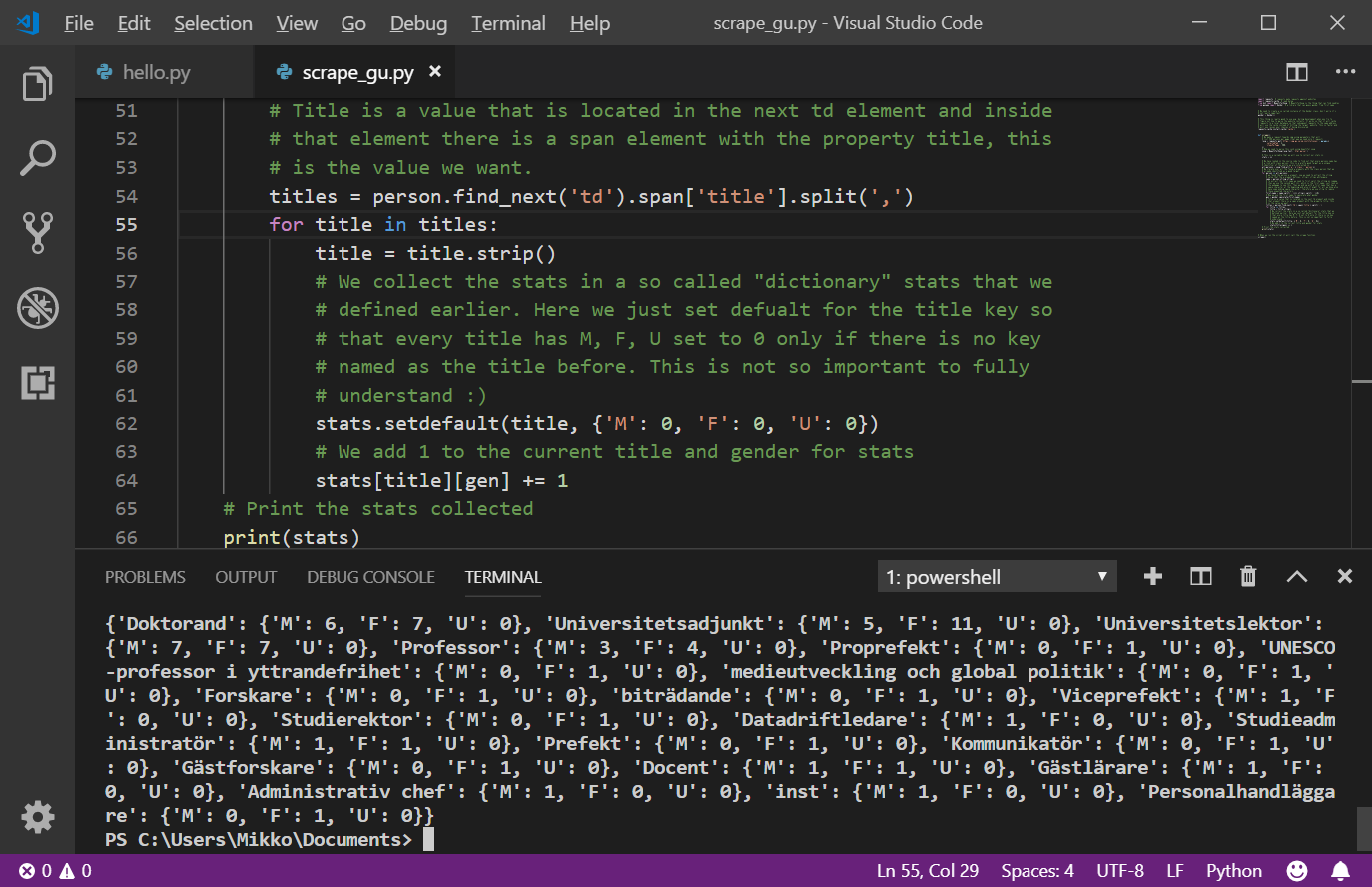
Save the file and run it, the output should be something along the lines of:
{'Doktorand': {'M': 6, 'F': 7, 'U': 0}, 'Universitetsadjunkt': {'M': 5, 'F': 11, 'U': 0}, 'Universitetslektor':
{'M': 7, 'F': 7, 'U': 0}, 'Professor': {'M': 3, 'F': 4, 'U': 0}, 'Proprefekt': {'M': 0, 'F': 1, 'U': 0}, 'UNESCO-professor i yttrandefrihet': {'M': 0, 'F': 1, 'U': 0}, 'medieutveckling och global politik': {'M': 0, 'F': 1, 'U': 0}, 'Forskare': {'M': 0, 'F': 1, 'U': 0}, 'biträdande': {'M': 0, 'F': 1, 'U': 0}, 'Viceprefekt': {'M': 1, 'F': 0, 'U': 0}, 'Studierektor': {'M': 0, 'F': 1, 'U': 0}, 'Datadriftledare': {'M': 1, 'F': 0, 'U': 0}, 'Studieadministratör': {'M': 1, 'F': 1, 'U': 0}, 'Prefekt': {'M': 0, 'F': 1, 'U': 0}, 'Kommunikatör': {'M': 0, 'F': 1, 'U': 0}, 'Gästforskare': {'M': 0, 'F': 1, 'U': 0}, 'Docent': {'M': 1, 'F': 1, 'U': 0}, 'Gästlärare': {'M': 1, 'F':
0, 'U': 0}, 'Administrativ chef': {'M': 1, 'F': 0, 'U': 0}, 'inst': {'M': 1, 'F': 0, 'U': 0}, 'Personalhandläggare': {'M': 0, 'F': 1, 'U': 0}}Is that good? Yes and no, it seems we did not take all that much care to some cases. We can see some titles like:
'biträdande': {'M': 0, 'F': 1, 'U': 0}'inst': {'M': 1, 'F': 0, 'U': 0}Those titles are probably not correct. What has gone wrong? Looking more closely at the data it seems that comma is used to separate titles but it is also used inside some titles. This is a quite common situation, the data is (hopefully) well enough structured for us humans to understand but not optimal for machines to parse. After reading the titles again and trying to figure out if there is some structure that we can exploit we note that all the different titles in the title string start with a capital letter. If we have a comma followed by a space character followed by a capital letter then we have a new title. Then we look up on the internet that we can split the title string on this fact by changing:
titles = person.find_next('td').span['title'].split(',')To:
titles = person.find_next('td').span['title']
titles = re.split(', (?=[A-Z])', titles)That looks complicated! Yes, you don’t have to know the details of this other than we used something called regular expressions. The logic however, is pretty easy to understand in what it does, we already defined the conditions needed for a split of titles:
- First we want a comma
- Then we need the following character to be a space
- Lastly we need the next character to be an upper character.
To use these regular expressions we need to import re, you can do this at
the top of your file, like this:
import re # add this line!
import requests
import requests_cache
from bs4 import BeautifulSoup
from gename import Gender
# ...
# and so on...Save the program and run it again: python scrape_gu.py.
Here is the full program code after our changes but without comments for
reference:
import re
import requests
import requests_cache
from bs4 import BeautifulSoup
from gename import Gender
gender = Gender()
requests_cache.install_cache('cache')
def scrape():
resp = requests.get('https://jmg.gu.se/om-institutionen/', params={
'selectedTab': 2,
'itemsPerPage': 500,
})
soup = BeautifulSoup(resp.text, 'html.parser')
stats = {}
all_persons = soup.find_all('a', {'class': 'person'})
for person in all_persons:
name = person.string.strip()
first_name = name.split(',')[1].strip().split(' ')[0]
gen = gender.speculate(first_name)
titles = person.find_next('td').span['title']
titles = re.split(r', (?=[A-Z])', titles)
for title in titles:
title = title.strip()
stats.setdefault(title, {'M': 0, 'F': 0, 'U': 0})
stats[title][gen] += 1
print(stats)
scrape()Run the program again and now we have some great success:
{'Doktorand': {'M': 6, 'F': 7, 'U': 0}, 'Universitetsadjunkt': {'M': 5, 'F': 11, 'U': 0}, 'Datadriftledare': {'M': 1, 'F': 0, 'U': 0}, 'Professor': {'M': 3, 'F': 4, 'U': 0}, 'Prefekt': {'M': 0, 'F': 1, 'U': 0}, 'Proprefekt': {'M': 0, 'F': 1, 'U': 0}, 'Administrativ chef, inst': {'M': 1, 'F': 0, 'U': 0}, 'Gästlärare': {'M': 1, 'F': 0, 'U': 0}, 'UNESCO-professor i yttrandefrihet, medieutveckling och global politik': {'M': 0, 'F': 1, 'U': 0}, 'Universitetslektor': {'M': 7, 'F': 7, 'U': 0}, 'Studierektor': {'M': 0, 'F': 1, 'U': 0}, 'Forskare, biträdande': {'M': 0, 'F': 1, 'U': 0}, 'Personalhandläggare': {'M': 0, 'F': 1, 'U': 0}, 'Docent': {'M': 1, 'F': 1, 'U': 0}, 'Gästforskare': {'M': 0, 'F': 1, 'U': 0}, 'Viceprefekt': {'M': 1, 'F': 0, 'U': 0}, 'Kommunikatör': {'M': 0, 'F': 1, 'U': 0}, 'Studieadministratör': {'M': 1, 'F': 1, 'U': 0}}That looks aweful and my eyes hurt
Right, so, the output is not pretty, can we do something about this? Can we at
the very least have some sane line breaks to make the output more readable?
There is a module called pprint for pretty printing available in the so
called standard library in python, let’s
try that. At the top of our script we need to import it first, change your
program like this:
import pprint # add this line!
import re
import requests
import requests_cache
from bs4 import BeautifulSoup
from gename import Gender
# ...
# and so on...And then we use the pretty printer instead of print, old code:
print(stats)New code:
pprint.pprint(stats)Running the program now yields something like this:
{'Administrativ chef, inst': {'F': 0, 'M': 1, 'U': 0},
'Datadriftledare': {'F': 0, 'M': 1, 'U': 0},
'Docent': {'F': 1, 'M': 1, 'U': 0},
'Doktorand': {'F': 7, 'M': 6, 'U': 0},
'Forskare, biträdande': {'F': 1, 'M': 0, 'U': 0},
'Gästforskare': {'F': 1, 'M': 0, 'U': 0},
'Gästlärare': {'F': 0, 'M': 1, 'U': 0},
'Kommunikatör': {'F': 1, 'M': 0, 'U': 0},
'Personalhandläggare': {'F': 1, 'M': 0, 'U': 0},
'Prefekt': {'F': 1, 'M': 0, 'U': 0},
'Professor': {'F': 4, 'M': 3, 'U': 0},
'Proprefekt': {'F': 1, 'M': 0, 'U': 0},
'Studieadministratör': {'F': 1, 'M': 1, 'U': 0},
'Studierektor': {'F': 1, 'M': 0, 'U': 0},
'UNESCO-professor i yttrandefrihet, medieutveckling och global politik': {'F': 1,
'M': 0,
'U': 0},
'Universitetsadjunkt': {'F': 11, 'M': 5, 'U': 0},
'Universitetslektor': {'F': 7, 'M': 7, 'U': 0},
'Viceprefekt': {'F': 0, 'M': 1, 'U': 0}}I think that is good enough, most of the time we would want to insert this data into a database or save it in some format readable by Excel and so putting more time into pretty printing is kind of almost like wasting time.
I hope you had fun, this marks the end of this series. I know I also talked
about using this program to look at the gender distribution on other GU
institutions, I will leave that as an exercise :) A hint is to change the
scrape function to accept a url parameter.