Scraping 101 Part 3
Looking back
That wasn’t so hard, you just scraped a website using python. The question that you could be asking is how did that happen? You’ve looked through the heavily commented code that we used but still… Let’s go back, way back.
We will now go though the steps that we needed to take before even writing our program in order to reach our goal that we defined in part 2 (find the gender distribution at the JMG institution).
Find the staff page
This is the first step towards our goal, we just go to https://jmg.gu.se/ Then
navigate to the page “Om institutionen”, that looks interesting, then click
“Personal”. Ok, there is some kind of list and the address (url) is
https://jmg.gu.se/om-institutionen#tabContentAnchor2 . Right, so now we have an
interesting list of staff there but there is also another interesting option to
list 500 people/page, that is better because then we don’t need to scrape
several pages to fetch all the names and titles that we are interested in. When
you click Visa 500 per sida you can see that the url changed to
https://jmg.gu.se/om-institutionen/?selectedTab=2&itemsPerPage=500 .
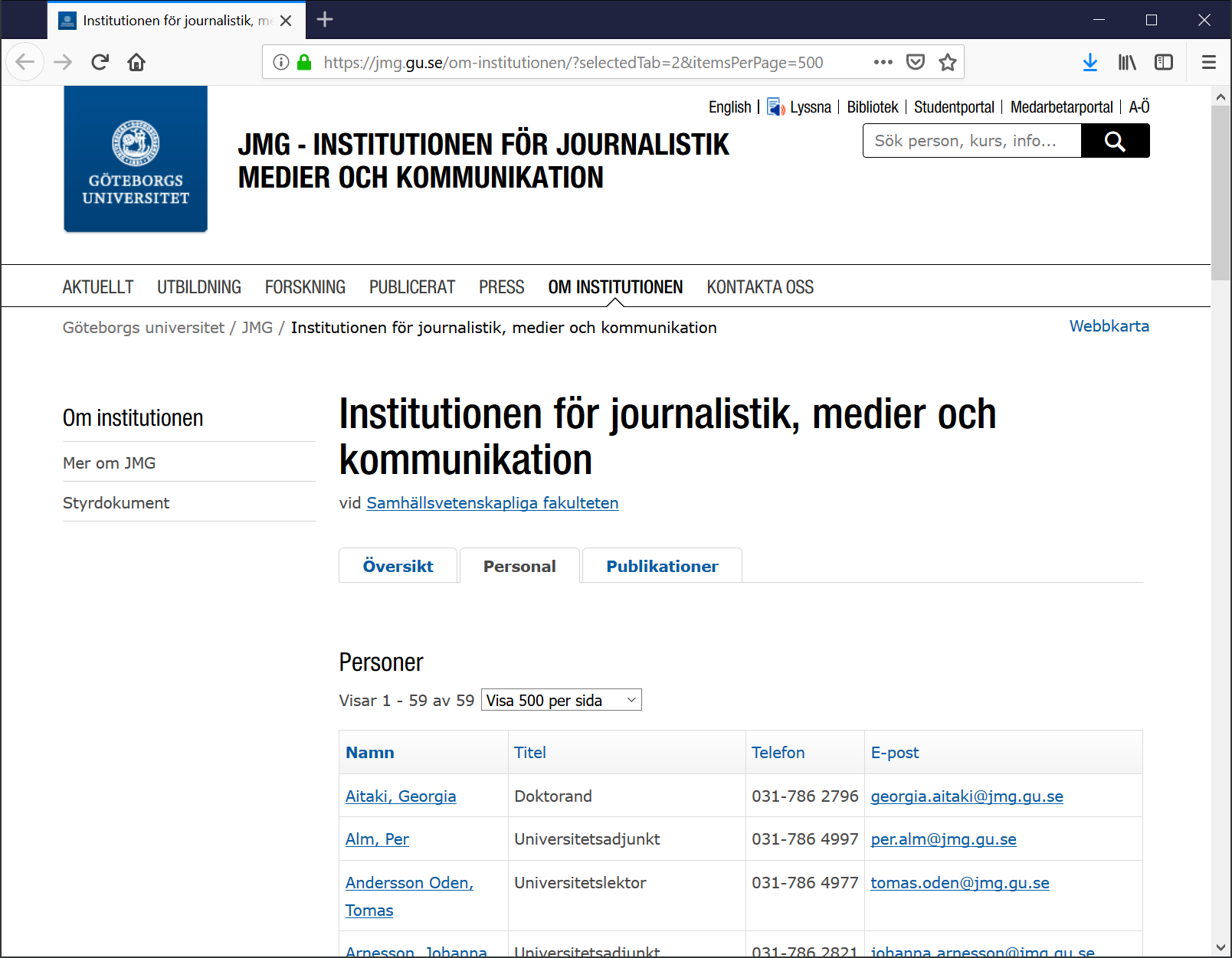
Great, this page contains the data we need, now we just need to find it in the source code.
How to reach the interesting data
This is perhaps a somewhat difficult step because you need some idea of how
HTML works. We need to look at the source and find some pattern that can
be exploited to find the specific data that we are interested in. I use the
browser Firefox to do this but you can use any other browser really. The way
that I will go about this is to select some interesting point on the page
and then right-click and choose Inspect Element when I am right over one
of the titles, Doktorand. This is what I will see then:
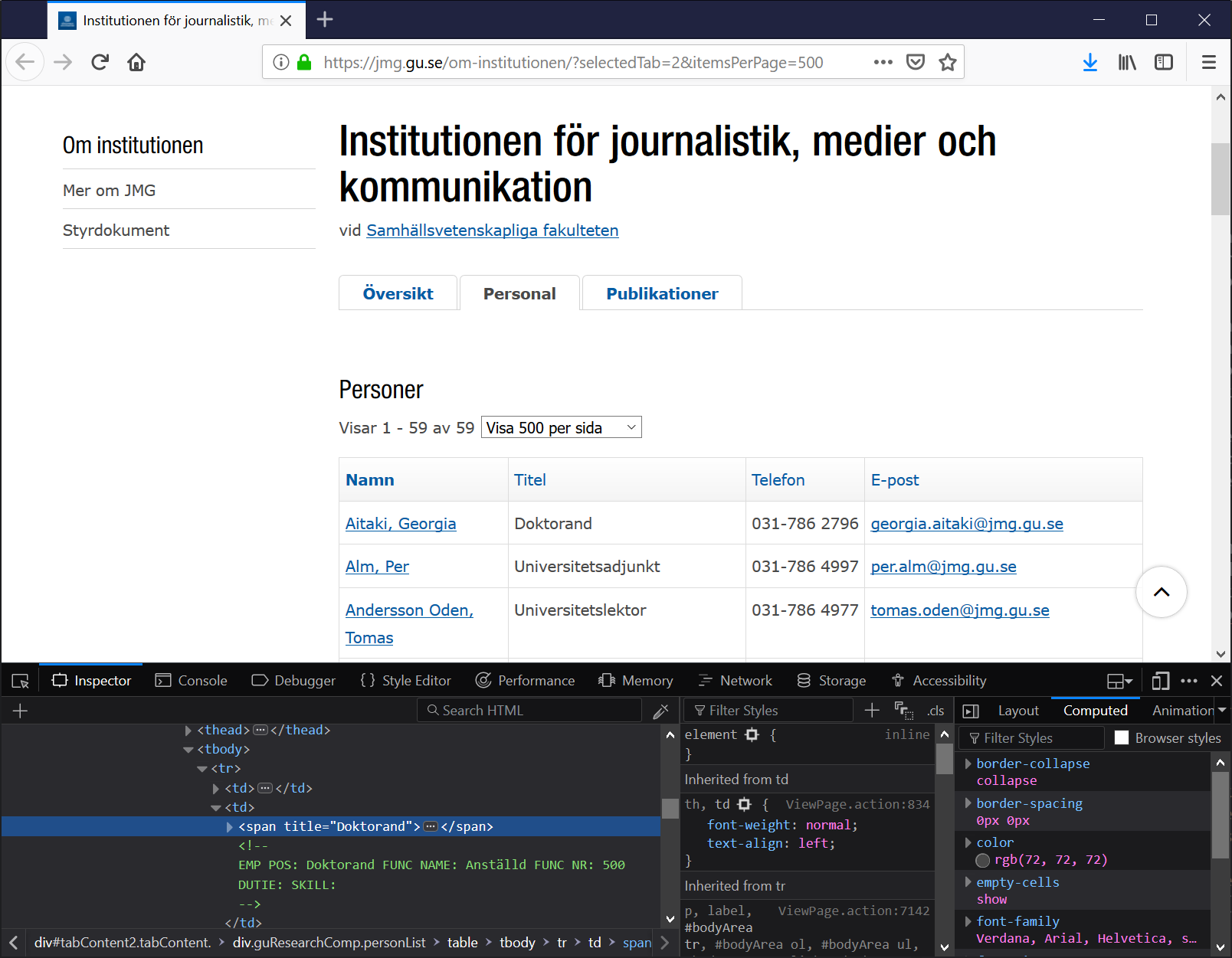
There we see that the tag <span> with the property title holds the title.
You could guess that this will be unique in the sense that if we search
through the document in full for all <span> tags with the class title then
we will only pick up the titles we are interested in, it seems likely.
But wait, we also need to figure out how to reach the name, the first name in
particular. We navigate in the first pane were we can see the source code
in Firefox and we figure that the name actually is shown before the title, so
we click on the <td> tag in the HTML tree that is before the <td> tag that
we had open to find the title:
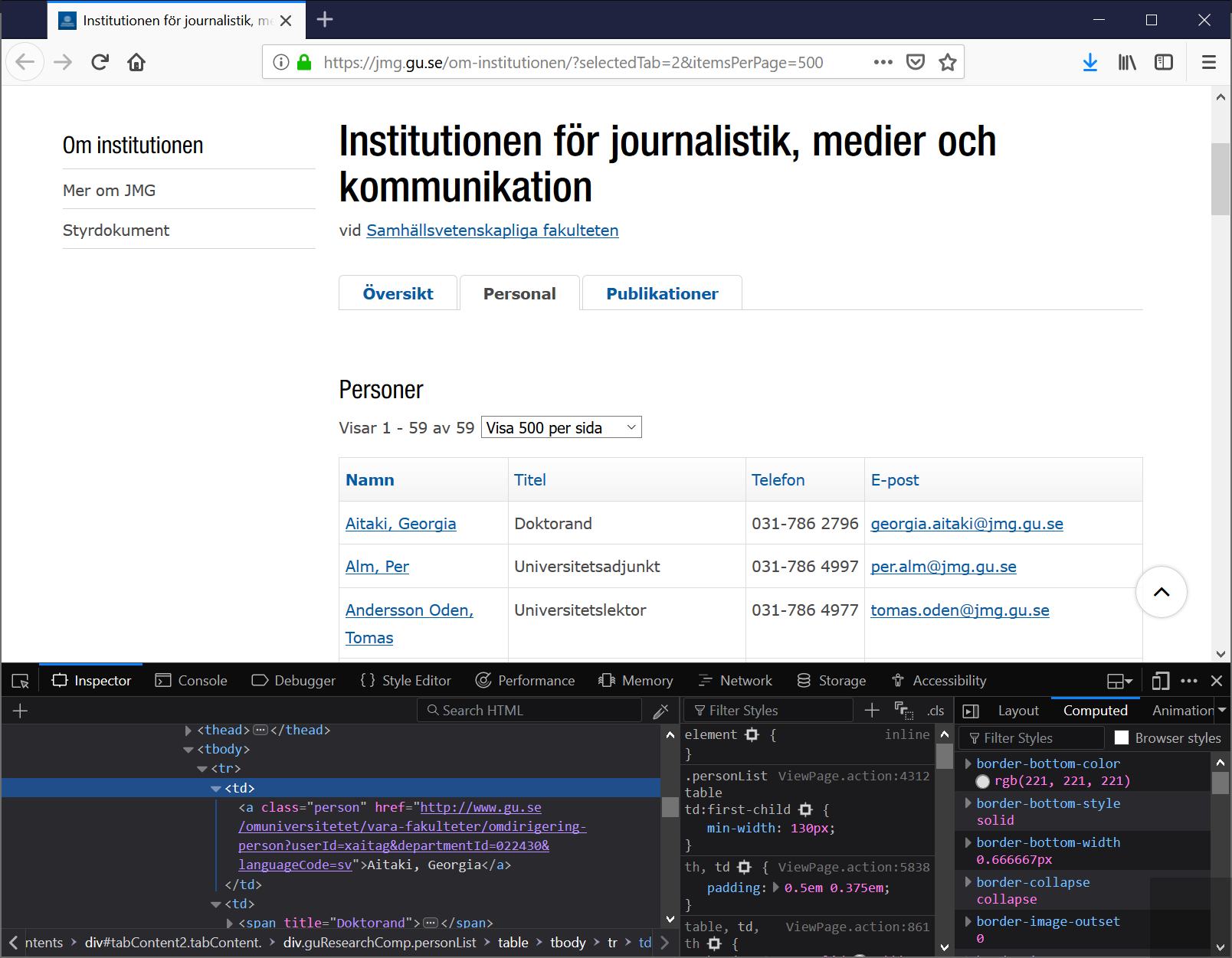
It looks like we are in luck, the persons name is right there in the <a> tag
inside the <td> tag. I’m saying we are lucky, that is because this will be
fairly easily reached, and normally it is not this easy.
Code walk through
You will notice a lot of comments in the code that we used, here I will just focus on the actual code, find the lines of code in your editor:
resp = requests.get('https://jmg.gu.se/om-institutionen/', params={
'selectedTab': 2,
'itemsPerPage': 500,
})?queryparam1=hello&queryparam2=world and so on at the end of the url. The
object resp is now the response from that request.
soup = BeautifulSoup(resp.text, 'html.parser')resp contains some more data than the actual HTML that the
request should have returned but to access the HTML we type resp.text. We
create a BeautifulSoup instance with the arguments resp.text and
'html.parser' and store that in a variable called soup. Perhaps those
technical terms in that sentence intimidated you, I will try to give a short
explanation of those terms. Now a class is often written with capital letters,
such as Gender or BeautifulSoup, that is just convention. Think of class as
a model, a representation, a higher description of something. If you are
familiar with philosophy it would be similar to the concept type in the context
of type/tokens. There is this class and when you want to use it, normally you
would instantiate it, from a class you get a class instance by putting
parenthesis after the class name. In those parenthesis you can also pass
values, these can be values that some classes use to make the instance in some
particular manner, so that it will have some property. The values that we pass
to the instantiation of the class BeautifulSoup are resp.text which is the
HTML document and 'html.parser' which just tells Beautiful Soup to create a
class instance that parses HTML.
all_persons = soup.find_all('a', {'class': 'person'})soup which basically is our
HTML document for the page wrapped in an easier-to-access-interesting-stuff object. This is what
BeautifulSoup is good for, you feed an HTML document into it, BeautifulSoup
then parses it and makes it searchable in many different ways. Now, we want to
search this object for all the <a> tags with the class person, that is
exactly what the part find_all('a', {'class': 'person'}) does. Note that a
class in HTML is something entirely different than a class in python. In HTML, class is
a property on the HTML tags, such as <a class="person">. Anyway, we conclude
that the object all_persons contains a list of all <a> tags with the class
person (this is not exactly true but it serves as a working model). Now we
want to iterate through all these persons, find their names and academic titles
and also their gender somehow. The for directive:
for person in all_persons:before our “persons list” all_persons is what you might guess a way to do this, for every
loop it will assign the next person from all_persons to the variable person.
That means that within the for loop, we have access to an object named person,
this object somehow holds the data we want.
For every person then
name = person.stringperson object is just a wrapped <a> tag and to access a Beautiful Soup
representation of an <a> tag’s content, we just type person.string.
The next line in the code that is not a comment reads:
first_name = name.split(',')[1].strip()gen = gender.speculate(first_name)gen now
holds the gender information and you are right, you don’t need to know the
details really. Just keep in mind that the
program is not 100% accurate, there are
unisex names for example. It should however be accurate enuogh for our purposes.
Now get the person’s title and we are done collecting:
title = person.find_next('td').span['title']<a> tag to the title, it’s pretty self explanatory really. What
I am saying is that you should be able to read it, writing the code is
somewhat more tedious work usually, you need to test, read documentation for
beautifulsoup, test again and so on until progress.
I’m going wild here to explain two rows of code in one go.
stats.setdefault(title, {'M': 0, 'F': 0, 'U': 0})
stats[title][gen] += 1for loop, to which we add all the stats to on
every loop iteration. The second row adds a 1 to the title/gender combination
for the current person, so the stats collected is just a counting operation.
Presentation
When the for loop is done, just print the thing. As you can notice the line is
not indented as much as the lines inside the for loop, it will be executed when
the for loop is done and the list of persons is exhausted.
print(stats)As we already talked about, there are some improvements we can make. Parsing the title better, parsing the first name more accurately and also maybe the print out could be improved upon for a nicer presentation of the results. There are also some other things we can do now that we have the code to parse the JMG institution page, since it is part of GU, maybe we can use the same code for other institutions?
Now go to the next exciting Part 4 of Scraping 101!!!